Every manager and senior leadership acknowledge the importance of performance testing. However, stakeholders must make many non-technical and strategic decisions, and they should be aware of and prepared to make those decisions. When starting a large green field project, while the leadership and SI vendors prepare the ways of working, aspects like performance testing should be discussed more upfront.
This has been crossposted to here
When starting the discussion about performance testing, many people think and discuss only tools like JMeter or LoadRunner. Another critical aspect that everyone agrees on is the load splitup and load profile for various screens/APIs. While they are essential and do a heavy-duty job, the following should precede the script preparation.
- Performance testing sign-off KPIs.
- Performance strategy — Bottom-up testing or Top-up testing approach.
- Dependent services. Approach and tools for virtualizing and mocking them.
- Test data preparation.
- Environment preparedness. The environment here refers to the primary, other applications, and dependent services invoked during the performance testing.
- Which metrics and benchmarks should the testing team consider when evaluating the test results? The testing team looked at our project’s 99 percentile response time, while the 95 percentile should have sufficed. Earlier alignment on such small guidelines will save a lot of time.
- Impact of other changes (e.g., security requirements and UI changes) in performance testing.
In an agile environment, these challenges grow if stakeholders do not make critical decisions in an appropriate early stage. The hidden costs could be much higher as they affect the project’s go-live date.
In a greenfield fintech implementation, we faced various challenges. Given that the concurrent users to support are 150K, and the user base is around 60 million, it took a lot of work to find an expert in performance testing who could anticipate the challenges and guide us effectively. Most performance testing experts limit their expertise to tools and rarely have a big picture.
Since our application depended on various enterprise services and systems hosted on-prem, they do not have a performance testing environment. While their production systems are stable and handle such a load, the lack of a performance testing environment forced us to adopt the following strategy.
- Initial benchmarking and sign-off testing will be carried out using virtualized services.
- Once the benchmarking is successful with virtualized service, test one of the lower external services and systems environments. Extrapolate the results accordingly.
Key Decisions
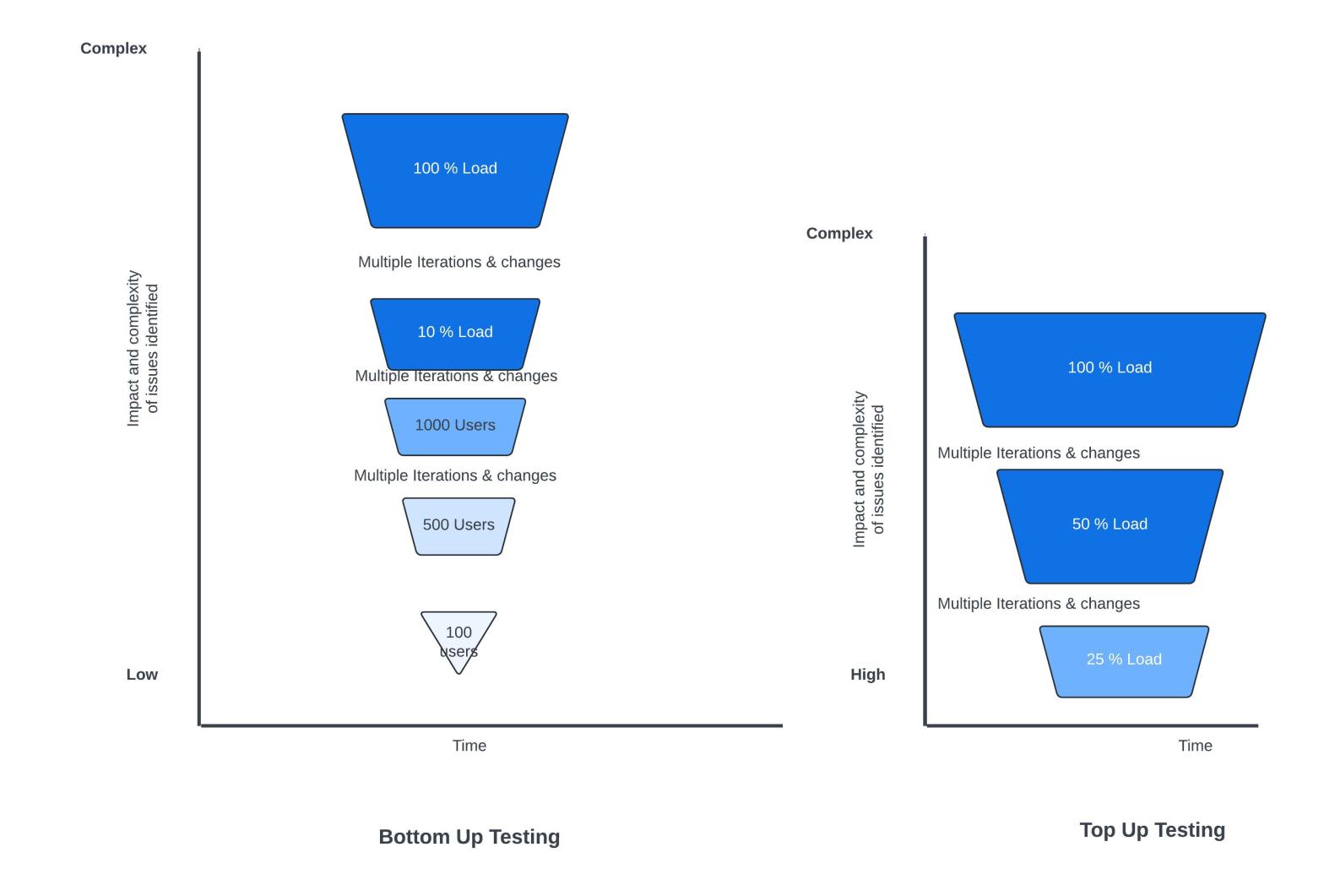
Bottom-up or Top-Up testing
Bottom- Up testing:
In bottom-up testing, we test with incremental loads, find issues, fix them, and proceed to the next iteration. While this approach is intuitive, it works only in the following scenarios.
- When the performance testing happens along with feature development.
- The architecture and design of critical components have been independently agreed upon and validated for performance.
- UI development is complete, and the product and testing teams have approved the functionalities tested and will not be changed immediately. If the look and feel of the pages change, the performance test scripts also need to change.
- The application and testing teams have finalized the data ingestion strategy for performance testing.
Top-Up Testing
In top-up testing, you start with a reasonably higher load (e.g. 10% of the peak load), test it and work on it based on the action items. Below are the key benefits
- The performance testing team catches key architecture and design decisions that impact performance early. In the bottom-up approach, minor design issues local to the functionality are only observed in the initial days. In any business-critical and high-impact application, problems on a large scale due to architecture limitations must be identified as early as possible. While individual infrastructure services might be scalable, their usage in the project-specific context can be surprising. In our application, we used ActiveMQ to transmit a heavy payload, which affected the environment’s stability as ActiveMQ space was filled up quickly. While ActiveMQ generally will handle the load, in our specific context, we realized that there are better fits for our use case than ActiveMQ.
- Get an overview of the infrastructure requirement to support the initial load or phases, which helps with budget forecasting and planning. While any changes to improve performance will only decrease the cost, the worst-case scenario has been accounted for.
- Roles and bottlenecks due to different teams are identified early in the project lifecycle. This earlier identification gives all team members, including the Infrastructure, network, and application teams, the required time to troubleshoot and fix the problems.
When to use the Top-Up approach
- Architecture and design evolve as the application develops.
- When the application is complex with various services, various infrastructure components and services are new to the project members and the organization (at this scale).
- When the organizations are ready to invest in additional performance testing infrastructure.
- When the quicker time to market outweighs the additional infrastructure cost spent on over-provisioning the infrastructure till the infrastructure is optimized.
While the starting point differs between the approaches, it is much more than that. The moment management decides on a strategy, the level of preparation and dependencies will vary. The impact of such a simple decision is immense, and the value and the time they give back are invaluable.
Services Virtualization
Service virtualization is an overlooked aspect while preparing the project for performance testing. While products can accelerate it, they come with additional licensing costs and infrastructure requirements. Also, SI develops the software in its environment and ships the final software to the customer. In that case, it does not have the opportunity to perform minimum viable performance testing with a reasonable load, which can give confidence to management.
Another aspect is data consistency. If only certain services are virtualized and others are not, the impact of the data inconsistency on the test scenarios, test scripts, etc., needs to be considered.
When using virtualized services for a performance testing team, the testing team should ensure that the latencies are ingested when the virtualized service returns the responses. This will give the results more credibility and bring results closer to the production behaviour.
Test Data Preparedness
The ease and complexity of preparing test data are proportional to the heterogeneity, variety, number and complexity of the services involved in the application. In a microservices architecture, every service will/can have its schema. While this gives the impression that the modular approach to creating test data is straightforward, the complexity comes when there is a soft dependency between various schemas. If the data are not consistent, then the scripts will fail.
When an off-the-shelf product is customized and implemented, the application teams will be comfortable with the APIs and the service payload that ingest the data but might need to be fully conversant with the data models and ingestion. Using APIs for data ingestion will practically work; it takes a lot more time than SQL or script-driven data ingestion.
In a large data setup, application teams must prioritize and dedicate their time to helping the performance testing team set up the test data.
The program and project plan should account for such overheads so that SI and the development team are better prepared.
The application team’s effort spent on test data preparedness cannot contribute to the immediate spring goals or provide tangible deliverables for the functional testing and business teams. However, the management should accept this and appreciate the long-term impact these efforts by the application development team will bring. In our program, we requested the performance testing team to use the APIs to set up the data, which delayed the data setup phase by a couple of (precious) months.
Impact of other changes on performance
Apart from performance, below are a few NFRs which influence the architecture decisions and can have a significant impact on the performance
- Application/API Security
- Regulatory compliance
- Auditing and Logging
- PCI and PII data security
- Infrastructure security components (DDoS protection rules, etc.)
- Fraud identification/prevention(Mostly in financial applications)
- Reporting and analytics
It is recommended that the approach for these NFRs be also discussed, agreed upon, and performance tested early in the project/program’s lifecycle. While technical architects can improvise the strategy in a pure agile manner, the cost and risks of implementation increase exponentially if these NFRs are architected much later. Other NFR requirements that affect performance should be approached with a curious mind by various stakeholders and their relevance to the current time frame of application usage, target audience, target device, etc. They should be decided as a team if they need to be implemented or can be ignored. Many greenfield implementations could involve rewriting existing legacy applications. In such scenarios, NFRs of legacy applications should be approached differently in the new application as well.
